Blog
Perspectives et Idées.
-

Qu'est-ce qu'une DXP composable ?
La DXP composable est souvent présentée comme une plateforme digitale modulaire permettant aux entreprises de sélectionner et d’assembler différentes solutions spécialisées pour créer une suite sur mesure. Fonctionnant grâce aux API et aux microservices, elle promet une flexibilité totale en intégrant des outils provenant de divers fournisseurs, selon les besoins spécifiques de chaque organisation....
-
Accessibilité et conception de site web : mise en conformité ou refonte ?
Découvrez les enjeux, méthodes et bonnes pratiques pour rendre votre site web accessible, durablement et simplement.
-

Site web : 12 outils pour vos tests d'accessibilité
Le test d'accessibilité de vos sites web est généralement la première étape avant de mettre en marche un travail de mis en conformité. Voici 12 outils pour vous y aider.
-

DXP vs CMS: Lequel choisir ?
Vos équipes gèrent des environnements numériques complexes : plusieurs sites web, portails internes, contenu multilingue. Cela vous semble familier ? La pression pour offrir des expériences transparentes, sécurisées et personnalisées n'a jamais été aussi forte. Vous vous posez certainement des questions : Un CMS est-il suffisant ou est-il temps d'adopter un DXP ? Selon Statista, les dépenses mondiales...
-
.jpg?t=w540)
Top 8 des alternatives à Liferay en 2025
Liferay est une solution populaire sur le marché des Digital Experience Platforms (DXP), notamment du fait de sa modularité et de son approche open-source. Elle permet aux entreprises de bâtir des portails web et intranets sur mesure avec des capacités multisites et multilingues. Mais la solution peut rapidement se révéler lourde à déployer et complexe à administrer. Entre les coûts cachés, les exigences...
-
.jpg?t=w540)
Comment choisir une plateforme d’expérience digitale (DXP) ?
Les attentes des clients d’aujourd’hui vont bien au-delà d’un simple site web. Ils recherchent des expériences personnalisées et fluides, quel que soit le canal utilisé pour interagir avec votre marque. C’est pourquoi choisir la bonne plateforme d’expérience digitale (DXP) est essentiel : c’est elle qui vous permettra de connecter efficacement avec vos clients sur tous vos canaux numériques. Un DXP...
-

Quel est votre écosystème d’expérience client ?
Dans un monde où la fidélité des clients est difficile à obtenir et facile à perdre, les entreprises doivent aller au-delà des simples points de contact et se concentrer sur l’ensemble de l’écosystème de l’expérience client (CX). Un écosystème CX bien orchestré garantit que chaque interaction qu’un client a avec votre marque – que ce soit via un site web, les réseaux sociaux, les canaux de support...
-

Comment construire une bonne stratégie d'expérience client en ligne ?
Découvrez comment améliorer l'expérience client en ligne grâce à des stratégies efficaces. Apprenez à concevoir une stratégie de CX numérique qui améliore l'accessibilité et fidélise les clients.
-

Digital asset management vs gestion électronique des documents
Découvrez la différence entre DAM et GED. Apprenez comment ces outils rationalisent la gestion du contenu numérique pour organiser les actifs créatifs ou les documents commerciaux essentiels.
-

Sites statiques vs. dynamiques : quelles différences ?
Découvrez la différence entre les sites statiques et dynamiques, leurs avantages et inconvénients, et comment notre solution DXP peut améliorer votre présence numérique.
-

Qu'est-ce que le développement web Entreprise ?
Découvrez ce qu'est un site web Entreprise et explorez des exemples. Apprenez comment le développement de sites web Entreprise permet à votre entreprise de disposer d'outils pour rester compétitive et stimuler sa croissance.
-
Qu'est-ce que le contenu en tant que service (CaaS) ?
Le contenu en tant que service (Content-as-a-Service - CaaS) aide les entreprises à fournir un contenu cohérent et personnalisé sur toutes les plateformes. Découvrez comment le CaaS peut améliorer votre gestion de contenu.
-

IA, SEO & Content Marketing : analyse de Karine Abbou
Explorez les tendances SEO 2025 et découvrez comment adapter votre stratégie de contenu à l’ère de l’IA générative grâce aux analyses de Karine Abbou.
-

Qu'est-ce que le cycle de vie du contenu ?
La gestion du cycle de vie du contenu couvre toutes les étapes, de la création à la suppression. Découvrez comment les différents types de contenu, tels que les livres blancs et les vidéos, suivent des processus uniques pour chaque phase.
-

Qu'est-ce que l'architecture de contenu et pourquoi est-elle importante ?
L'architecture de contenu est la clé d'un système de gestion de contenu efficace. Découvrez comment elle améliore l'engagement, l'évolutivité et la réussite. Lire l'article complet pour en savoir plus.
-

10 façons efficaces d'améliorer votre accessibilité Web
Apprenez à rendre un site web accessible à l'aide de bonnes pratiques et de fonctionnalités. Découvrez 10 façons d'améliorer votre accessibilité web et de créer une expérience en ligne inclusive pour tous.
-

IA : Conseils de Frédéric Cavazza pour votre transformation digitale
Fin 2024, la conférence d’ouverture de l’Intelligence Marketing Day, à Lyon, a pour thème : Tendances marketing et évolution des usages du numérique.
-

Qu'est-ce qu'un CMS Cloud ? Tout ce qu'il faut savoir
Découvrez ce qu'est un CMS Cloud et comment il transforme la gestion de contenu. Explorez ses avantages et apprenez à optimiser votre stratégie numérique pour l'avenir.
-

Replatforming CMS : stratégies, étapes et bénéfices
Découvrez les stratégies, les étapes et les principaux avantages d'un projet de replatforming CMS réussi. La réduction du nombre de plates-formes CMS existantes présente d'énormes avantages pour les grandes organisations.
-

Sécurité logicielle : les meilleures pratiques pour sécuriser les CMS
Découvrez les types et les exemples de sécurité logicielle, ainsi que les 5 meilleures pratiques pour sécuriser votre CMS, protéger les données sensibles et prévenir les cyberattaques.
-

Alternative à AEM : pourquoi les développeurs et les architectes devraient considérer Jahia
Vous cherchez une alternative à AEM (Adobe Experience Manager) ? Voici un bref résumé décrivant la technologie derrière Jahia.
-
IA : ce qu’il faut savoir avant de mettre en place un PoC
Nous nous sommes donc rendus au Symposium Gartner, afin d’obtenir les dernières recommandations technologiques de l’analyste. Le sujet au cœur des débats ? L’IA.
-
Choisir le meilleur CMS multilingue
Choisir le meilleur CMS multilingue n'est pas simple. Voici donc une liste de vérifications à effectuer avant de faire votre choix. Le CMS Jahia offre des fonctionnalités avancées pour la gestion de plusieurs langues et est utilisé par des entreprises internationales et des ONG pour servir des sites web dans plusieurs dizaines de langues.
-

Playbook : 3 étapes pour intégrer l’IA à votre CMS
Nous avons recueilli les paroles d’experts afin de vous proposer une approche pertinente pour intégrer l'IA à votre CMS.
-

Sécurité des sites web : Pourquoi est-ce crucial pour votre entreprise ?
La sécurité des sites web est essentielle pour sécuriser votre système de gestion de contenu, protéger les données de l'entreprise et se défendre contre les cybermenaces. Lisez cet article pour savoir comment protéger votre entreprise.
-

Pourquoi aucun CMS n'est basé sur Spring framework / Spring Boot ?
Introduction Le framework Spring est formidable. La plupart des développeurs Java l'utilisent à un moment ou à un autre, et ils l'apprécient tous. Spring fournit une bonne injection de dépendances et de nombreuses autres bibliothèques (Spring Security, Spring Batch, Spring Boot, ...) pour résoudre les problèmes habituels auxquels les développeurs sont confrontés. Cela dit, Spring a des limites importantes...
-

Intégration DAM : comment connecter vos solutions ?
Les intégrations d'outils de Digital Asset Management (DAM) améliorent votre plateforme CMS. Découvrez comment l'utilisation d'intégrations peut rationaliser les flux de travail, augmenter l'efficacité et améliorer la collaboration au sein de l'équipe.
-

CMS Java headless - Guide pour les développeurs
Pour les développeurs Java : ce qu'il faut vraiment regarder lors de l'évaluation d'un headless Java CMS.
-
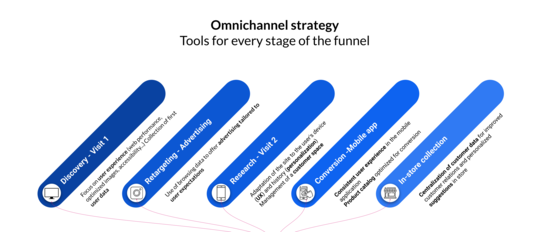
Outils pour une stratégie omnicanale pérenne
Adopter une stratégie omnicanale repose sur des outils bien intégrés qui permettent une gestion fluide du contenu et des données. Jahia combine un CMS flexible, une Customer Data Platform (CDP), et des connecteurs bidirectionnels pour une expérience unifiée et évolutive, offrant ainsi une alternative équilibrée entre la suite logicielle et la stack modulaire.
-

Développer un site web avec JavaScript avec la nouvelle stack front-end de Jahia 8.2
Communiqué de presse Genève, Suisse - Le groupe Jahia Solutions, acteur pionnier et open-source dans le domaine des Digital eXperience Platforms (DXP) , a officiellement lancé Jahia 8.2.0, une mise à jour majeure de son produit phare. Cette dernière version introduit des innovations majeures, notamment avec les modules JavaScript, conçues pour améliorer le développement front-end et rationaliser la...
-

CMS Cloud : 3 points d’attention pour votre migration
Migrer un site web ou un portail web Enterprise depuis un hébergement on-premise vers un hébergement Cloud nécessite plus que quelques clics et de la patience. Il ne s’agit pas simplement de transférer des données d’une boîte à une autre, mais bien d’adapter une infrastructure web à la structuration du cloud. Le process à l’origine devait être de faire un export du site par l’interface d’administration,...
-

Quelle solution de gestion de contenu pour un portail web ?
Quels sont les enjeux spécifiques de la gestion de portails web ? Et comment aller encore plus loin dans l'utilisation de votre portail ? C'est ce que nous vous proposons d'explorer dans cet article.
-
CMS JavaScript & Java user-friendly : découvrez Jahia 8.2
Avec la version 8.2 de Jahia, le marché des CMS et DXP voit arriver une solution pensée à la fois pour les développeurs et les contributeurs.
-

CMS avec hébergement Cloud : quels outils de suivi et de surveillance ?
Découvrez les possibilités de suivi et de surveillance disponibles dans un CMS hébergé sur le Cloud, et le rôle du monitoring dans une gestion optimisée de la performance et de l'expérience utilisateur.
-

Projet web : quelles compétences recruter pour constituer votre équipe ?
Identifiez les compétences essentielles à recruter pour réussir un projet web : stratégie digitale, UX/UI design, contenu & SEO, sécurité... Mais surtout développement web.
-
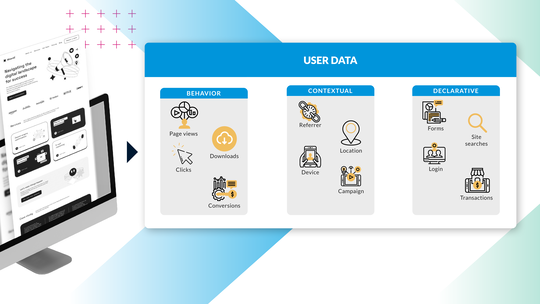
Conversion : 3 étapes indispensables à votre stratégie de personnalisation
Dans cet article, je vais vous expliquer comment réaliser une personnalisation pertinente à grande échelle.
-

La vérité à propos du Headless
Avant d'écrire cette entrée de blog, j'ai passé beaucoup de temps à lire ce qu'internet avait à dire au sujet du Headless. Des billets de blog souvent partisans ou biaisés par le point de vue de leurs auteurs - c'est souvent le cas au sujet du Headless - se focalisant principalement sur les attraits techniques de la démarche. Nous avons passé ces dernières années à collaborer à un grand nombre de projets...
-

4 étapes pour personnaliser le parcours web de vos clients
Soigner l'expérience clients sur les points de contact physiques (points de vente ou contacts téléphoniques en particulier) est toujours un élément qui fait la différence dans une relation commerciale. Pensez à Décathlon, Nescafé, Starbuck's ou Apple. Comme l'a bien dit Jeff Bezos : “If you do build a great experience, customers tell each other about that. Word of mouth is very powerful.” Voilà la...
-

Moteur de recherche interne : 4 bonnes pratiques pour améliorer l’expérience web de vos visiteurs
Si l’expérience utilisateur est un facteur important dans votre stratégie digitale alors avoir un moteur de recherche performant sur votre site internet ou votre portail web est aujourd’hui indispensable. Les personnes qui utilisent le moteur de recherche de votre site sont : soit dans la position où elles savent déjà exactement ce qu’elles recherchent soit dans la position où elles n’ont pas trouvé...
-

Créer une expérience digitale grâce à votre CMS
Digital Experience : Transformer votre site web en un outil interactif et personnalisé. Faites vivre à vos utilisateurs une expérience unique grâce à votre CMS.
-

FTR : Jahia réaffirme ses engagements en matière de sécurité avec Amazon Web Service (AWS)
Avec la certification Foundational Technical Review, Jahia Solutions franchit une nouvelle étape dans sa collaboration avec Amazon Web Services, et réaffirme ses engagements en matière de sécurité.
-

Performances de votre site web : le poids des images
Quand on parle des performances d'un site web et d’optimisation, le poids ou la taille des images est ce qui vient le plus naturellement à l’esprit : moins les images sont lourdes, plus rapide sera le chargement de vos pages, meilleure sera l’expérience de navigation de vos utilisateurs, et votre positionnement sur les moteurs de recherche avec. Notre partenaire Scaleflex, qui propose une solution spécialisée sur le sujet, a accepté de nous donner quelques éléments pour vous aider à optimiser les performances de votre site internet.
-

Décuplez vos performances SEO grâce à Semji en accès direct dans votre CMS
En bref Jahia s’appuie sur un framework permettant aux organisations de créer des sites optimisés pour le référencement naturel (SEO). Les performances SEO techniques de nombreux sites réalisés avec Jahia atteignent des scores compris entre 90 et 100 dans Google Lighthouse. Grâce au partenariat conclu entre Jahia et Semji, vous avez désormais accès, en plus de ce socle de performances SEO techniques,...
-

Keepicker : un DAM intégré à votre CMS pour une meilleure gestion de contenus
Le DAM Keepeek fait désormais partie de l'écosystème digital de Jahia : une solution performante qui facilitera encore plus la gestion des contenus dans votre CMS.
-

CMS Open Source : Définition, explications et comparaison
Dans cet article, nous examinerons ce qu'est un CMS open source, comment il fonctionne et qui peut en tirer le meilleur parti.
-
Qu'est-ce qu'un Portail Web ? (Mise à jour 2025)
De l'intranet à l'extranet, le portail web s'est imposé comme un outil en ligne de premier plan pour les entreprises de tous les secteurs. Mais il n'est pas toujours facile de définir exactement ce que ce terme recouvre.
-

Pourquoi opter pour un portail client en B2B ? Les avantages et les enjeux pour votre entreprise
Réseaux sociaux, recherche en ligne, relations plus directes avec les clients : le commerce B2B évolue. Les acheteurs professionnels recherchent une expérience conviviale et personnalisée, et accordent beaucoup d’importance à la réactivité et à la disponibilité des informations en ligne. La liberté et le confort assurés par un portail de commande sont devenus des critères de différenciation essentiels...
-

Le portail fournisseur : comment il booste votre productivité et renforce vos relations commerciales
E-procurement, e-sourcing, e-invoicing… Les relations entre prestataires et clients évoluent et se digitalisent toujours plus ! Performance, souplesse et simplification font figure d’impératifs. Au cœur de ce mouvement, un outil s’affirme comme essentiel : le portail fournisseurs. Cette plateforme collaborative présente de nombreux avantages, parmi lesquels la centralisation des données, l’homogénéisation...
-

Portail self-service numérique : ce qu’il faut savoir avant de lancer votre stratégie
Le Portail en libre service, ou portail self-service, offre une expérience simple, personnalisée, et actionnable en toute autonomie. Découvrez pourquoi et comment mettre en place le vôtre.
-

Comment choisir la plateforme optimale pour construire votre portail web : le guide complet
Dans le paysage numérique d’aujourd’hui, le succès d'un portail web ou d'une interface utilisateur repose sur sa plateforme sous-jacente. Au vu du nombre d'options et de fournisseurs disponibles, il est d'autant plus essentiel de trouver une solution de portail qui correspond à la vision et aux exigences de votre organisation. Ce guide vous accompagnera dans l’analyse de critères cruciaux, comme la...
-

CMS hybrides : définitions, explications et avantages
Naviguer entre les différents systèmes de gestion de contenu (CMS) peut s’avérer complexe. Le débat entre les CMS traditionnels, headless et hybrides se poursuit, chacun offrant des avantages spécifiques. Le CMS hybride combine les meilleures caractéristiques de ses homologues, alliant la facilité d'utilisation d'un CMS traditionnel à l'architecture flexible et résiliente des systèmes headless. Avec...
-

Avantages du CMS Headless Enterprise pour le multisite
Le choix du bon système de gestion de contenu (CMS) peut avoir un impact significatif sur la présence en ligne de votre organisation. Jahia, pionnier des CMS traditionnels et headless, s’est positionné comme un choix optimal pour les grandes entreprises à la recherche d'un équilibre entre flexibilité, fonctionnalité et design convivial. Dans cet article, nous allons examiner la pertinence de Jahia...
-

Du CMS headless au CMS Hybride : avantages, inconvénients et pertinence
Les systèmes de gestion de contenu (CMS) headless apportent flexibilité et scalabilité, et offrent des fonctions visant l’amélioration de la sécurité. Dans cet article, nous examinerons les bénéfices liés à l'utilisation d'un CMS headless, par rapport à un CMS traditionnel. Nous approfondirons ainsi ses avantages et inconvénients, ainsi que la pertinence de chaque approche. Ce panorama peut vous guider...
-

Développer une plateforme DXP avec la meilleure UX pour les utilisateurs métiers
La capacité des auteurs à accomplir leurs tâches quotidiennes de manière autonome et agile dépend directement de la qualité des solutions fournies par les développeurs, qui visent à offrir la meilleure expérience d'utilisation de la plateforme. Pour la création d'expériences web, les maquettes, la conception, les ateliers UI/UX et l'élaboration de parcours des utilisateurs constituent une base essentielle...
-
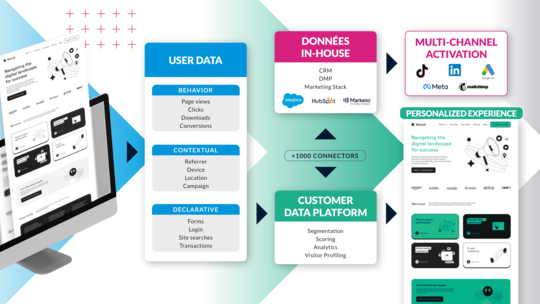
Qu'est-ce qu'une plateforme DXP (Digital Experience Plateform) ?
Une des questions qu'on nous pose le plus souvent est « C'est quoi une DXP ? » Il n'est pas difficile de comprendre pourquoi : depuis l'apparition de ce terme il y a quelques années, il semblerait que chacun soit parvenu à sa propre définition. De Gartner à Forrester, les définitions d'une DXP varient, laissant les professionnels de l'IT et du marketing comme les dirigeants d'entreprise dans une grande...
-

Jahia devient Cloud first
Depuis son lancement en 2018, Jahia Cloud nous a permis d’atteindre des objectifs ambitieux, tel que la migration de la majeure partie de notre activité vers le Cloud et l'hébergement de sites web extrêmement exigeants, le tout en offrant une facilité d’utilisation inégalée : nos clients Jahia Cloud font plus facilement, et plus régulièrement, des montées de versions afin de rester à jour et ainsi...
-

Customizing pickers in Content Editor 4.1
When contributing web pages, editors have to create links to other pages of interest for the visitors, use or reference contents which have been created in different locations on the site, add images coming from the DAM, etc. For all of these tasks, they need to go through a “picker” interface, so they can select the desired resources. Jahia provides a set of such pickers out-of-the-box, which are generic enough to address the most common use cases. But did you know that you can customize them to ease the content reference selection for your contributors?
-

Comment les intégrateurs peuvent-ils offrir une expérience optimale aux auteurs de contenu dans un CMS ? (Astuces pour les Intégrateurs Pt.1)
L'efficacité des équipes métiers est devenue essentielle dans une économie numérique en pleine expansion et ceci dans tous les secteurs. En tant qu'intégrateur, vous pouvez contribuer à fournir l'agilité et l'autonomie nécessaires aux organisations pour rester à flot et faire face à la concurrence efficacement en utilisant les bons outils numériques. Ceci est particulièrement pertinent dans la gestion...
-

Paroles de client - APEC
Rencontre avec Hélène Catinaud, Responsable de pôle Etudes et Développements à la Direction des Systèmes d'Information de l’APEC L’origine du projet Avant 2015, l'APEC, acteur de référence sur le marché des compétences cadres, utilisait deux CMS développés en PHP alors que le reste de leurs développements étaient faits en Java. L’organisation désirait harmoniser les technologies utilisées en passant...
-
Comment bien évaluer la sécurité de votre prochain système de gestion de contenu (CMS) dans le Cloud ?
Les répercussions des violations de la cybersécurité pour les entreprises sont importantes et vont bien au-delà de la perte de données, entrainant également une rupture de la confidentialité des informations clients et, en fin de compte, la perte de clients. Jamais dans l'histoire, il n'y a eu autant de données et autant de défis pour les protéger. Chaque brique de votre Platform d'Expérience Numérique...
-
Comment migrer sur Jahia Cloud en 5 étapes ?
Le processus de conversion d’une plateforme on premise vers le Cloud est souvent décrit à l'aide d'une série d'actions simples qui aboutissent finalement à une plate-forme migrée. En outre, si la plupart des gens s'accordent à dire que les migrations peuvent être réalisées en quelques heures ou quelques jours, il faut tenir compte du fait que la collecte d'informations et la planification des actions...
-

Headless CMS - Quelles fonctionnalités pour les marketers ?
Nombreuses sont les entreprises à vouloir se lancer dans un projet headless sans considérer les réels impacts que cette technologie peut avoir sur leur activité. Les CMS headless font beaucoup de promesses et mettent en avant leur "omnicanalité" et la compatibilité avec différents supports comme les applications mobiles, les montres connectées, les assistants vocaux, l'IOT… Seulement, cette vision...
-

5 étapes pour mettre en place une usine à sites
Les projets d'usine à sites sont particulièrement pertinents pour les entreprises et institutions avec plusieurs activités, d'importants volumes de contenus, des enjeux d'expérience utilisateur omnicanal ou encore de brand management (cohérence graphique et ou éditoriale). Voire tout ça à la fois. Dans cet article, nous vous donnons toutes les clés pour comprendre ce qu'est une usine à sites ("site...
-

5 actions pour optimiser votre référencement SEO
Le référencement naturel est un des principaux leviers d’acquisition de trafic vers votre site internet. Il est donc essentiel de le prendre en compte dans vos stratégies digitales et de contenus. Pour rappel, le référencement naturel ou référencement SEO comprend toutes les techniques visant à améliorer le positionnement de votre site dans les résultats des moteurs de recherche. Vous n’êtes pas un...
-

Comment aborder le processus de migration de Jahia 7 à Jahia 8
Jahia 7 a vu le jour en 2014. Six ans plus tard, nous avons décidé de remodeler notre interface utilisateur et d’effectuer des mises à niveau back-end majeures qui ont abouti à la sortie de Jahia 8. Généralement, les mises à niveau traditionnelles de Jahia consistent simplement à exécuter un patch de mise à jour. Toutefois, les changements majeurs introduits avec Jahia 8 impliqueront de vérifier et...
-

L’accessibilité numérique, première étape de la personnalisation
Vous voulez améliorer votre modèle d’acquisition et de fidélisation client ? Vous avez pensé à la personnalisation de l'expérience client ? Très bonne gymnastique mentale ! Mais saviez-vous que la première étape de la personnalisation devrait être l’accessibilité de votre site ? Surpris ? Vous pensiez plutôt A/B Testing, segmentation et données clients ? Pas de panique, l’un n’empêche pas l’autre !...
-

Jahia 8 : Une nouvelle interface utilisateur personnalisable
L’interface utilisateur (UI) de Jahia 8 utilise les technologies ‘front’ les plus récentes, facilitant ainsi la création d’extensions par des développeurs. Mais, quel impact peuvent avoir ces extensions pour les contributeurs de contenu ? Elles permettent une personnalisation plus aisée de l’interface pour répondre à leurs besoins métiers. Dans cet article, nous examinerons six exemples d’extension...
-

Paroles de clients - Lyon Métropole Habitat
Retour sur la collaboration entre Lyon Métropole Habitat et Jahia avec Christophe Simon, Chef de Projet à la Direction des Systèmes d’Information. Premier bailleur public de la métropole de Lyon, Lyon Metropole Habitat gère son site internet et son extranet client sur la plateforme Jahia depuis sa création en 2016. Avec ses agences de proximité, son site www.lmhabitat.fr est l’un des principaux points...
-

Développement de portail Open Source avec Jahia
Comment les portails web en java vous aident à intégrer des expériences numériques à travers différents points de contact pour offrir à vos clients à la fois personnalisation et cohérence.
-

CDP et DMP : les principales différences à connaître
Les données sont un élément essentiel dans toutes les dimensions du marketing digital. Dans tous les secteurs d'activité, les entreprises utilisent des solutions techniques diverses pour collecter des données et les transformer en informations exploitables. Parmi les options existantes pour gérer ces données, les plateformes de gestion des données (DMP) et les plateformes de données clients (CDP) sont...
-

Principaux cas d'usage des plateformes de données clients
Les plateformes de données clients (CDP) permettent de résoudre de nombreux problèmes liés à la gestion traditionnelle des données. Les entreprises ont parfois du mal à maximiser la valeur de leurs données lorsque celles-ci sont dispersées entre différents systèmes cloisonnés. Des données trop éparpillées sont un frein à la bonne compréhension du comportement des clients, et cela complique leur exploitation...
-

Plateformes d'expérience digitale open source : réinventez l'expérience client
Les plateformes d'expérience digitale (DXP) open source offrent aux entreprises les outils essentiels pour répondre aux attentes du consommateur moderne. Aujourd'hui, les clients attendent une expérience personnalisée et homogène sur tous les canaux de vente. Cela demande une collecte de données puissante et des logiciels à la pointe de la technologie. Selon Gartner, 27 % des marketeurs estiment que...
-

Maximisez vos données opérationnelles avec la CDP intégrée de Jahia
Si les données valent de l'or, alors la ruée vers cet eldorado a bel et bien commencé. Les entreprises n'ont pas eu d'autre choix que de se lancer dans l'aventure du digital. Elles ont dû apprendre à se fondre dans le paysage moderne et à interagir avec leurs utilisateurs à travers des points de contact toujours plus nombreux, tout cela dans le but de rester compétitives. L'une des conséquences indirectes...
-

Votre Stratégie Digitale : Est-ce le moment de la redéfinir ?
Petit rappel : votre stratégie digitale définit la façon dont votre organisation met en place sa technologie, s'adapte aux évolutions du marché et développe un moteur durable qui générera un véritable ROI pour vos efforts organisationnels et de marketing.
-

La DXP peut-elle engendrer des coûts cachés ?
Vous avez déjà acheté une voiture d'occasion ? Eh bien le processus d'achat d'une plateforme d'expérience digitale, ou DXP, est très similaire. Vous voulez savoir pourquoi ?
-

CMS vs DXP : quelles différences ?
Le monde Martech adore l'idée selon laquelle le choix entre CMS et DXP est une question déterminante pour toute organisation, mais en réalité ce débat est superficiel. Et voici pourquoi
-

Un système de gestion de contenu (CMS), c'est quoi ?
Avez-vous déjà entendu l'expression "le contenu est roi" (content is kind en version originale) ? Si vous travaillez dans le marketing ou l'informatique, alors vous savez qu'il ne s'agit pas seulement d'une expression répétée à l'envi.
-

Stack vs Suite : l'ère de la Stack est arrivée, hasta la vista les Suites !
Quel est le meilleur choix pour mon entreprise ? La Suite ou la Stack ? C'est une question qui taraude le monde de la tech depuis des décennies. Le débat oppose essentiellement les partisans d'une technologie marketing confinée entre les murs dorés d'un unique géant de la tech et ceux qui préfèrent s'aventurer dans le Far West technologique, en la confiant à des entreprises challengers plus petites...
-

L'innovation par itération
Dans de nombreuses entreprises technologiques, on entend souvent dire que la croissance passe par l'innovation. Que la finalité de l'innovation (créer la « next big thing ») est le marqueur ultime de la réussite, une promesse faite et tenue aux investisseurs, aux clients et à l'organisation dans son ensemble. Cet état d'esprit a engendré certaines des plus grandes technologies de ces dernières décennies,...