Blog
Insights from the digital edge
-

Jahia's Portal Management Guide
Jahia’s portal management system is built on the open source, digital experience (DXP) platform. This headless CMS environment makes managing portals simple.
-
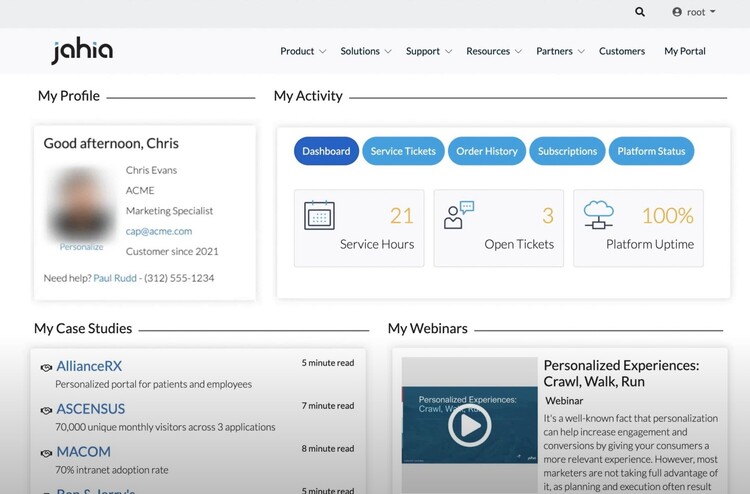
What is a web portal? (Update 2024)
From the Intranet to the extranet, the web portal has established itself as a leading online tool for companies in all sectors. But it's not always easy to define exactly what this term means.
-

How to Choose the Optimal Platform to Build Your Online Portal: A Comprehensive Guide
In today’s digital business landscape, a successful web portal, or user interface, depends on its foundational platform. There are many options and providers to choose from which makes identifying a portal platform that aligns with your organization’s vision and requirements that much more important. This guide will help explore crucial considerations such as compatibility, ease of use, scalability,...
-

Hybrid CMS Benefits for Content Management: Merging the Best of Both Systems
Navigating between content management systems (CMS) can be complex. The debate between traditional, headless, and hybrid CMS continues, with each offering unique benefits. However, the hybrid CMS stands out as a blend of the best features of its counterparts by merging the ease of use of a traditional CMS with the flexible, future-proof architecture of headless systems. Presenting lower startup costs...
-

Why Jahia is the Optimal Enterprise Headless CMS Choice for Large Businesses
Choosing the right content management system (CMS) can significantly impact your organization’s digital presence. Jahia, a pioneer in both traditional and headless CMS, has proven experience as an optimal choice for enterprise businesses seeking a balance between flexibility, functionality, and user-friendly design. In this article, we'll review Jahia's capabilities aligned with the five essential...
-

Understanding Headless CMS: A Comprehensive Overview Including Pros, Cons, and Suitability
Headless content management systems (CMS) offer flexibility, scalability, and the potential for improved security. This article explores the benefits of using a headless CMS and how it compares to a traditional CMS, including pros, cons, and suitability. This comprehensive overview can help you decide on the best CMS to fit for your organization’s needs and capabilities. Definition of Headless CMS...
-

5 Essential Factors to Consider when Selecting the Optimal Headless CMS as a Large Organization
Content is the currency of modern enterprise; choosing the right content management system (CMS) can be a game-changer for your business. Traditional CMS is typically a single monolithic solution to creating, managing, and publishing content including the front-end presentation, primarily on a web page. Today’s headless CMS decouple that relationship by not connecting with front-end presentation at...
-

How can the Jahia DXP platform help you? (Ingrators Tips Pt.2)
As presented in our previous article “How Integrators Can Design the Ultimate Content Author Experience in a CMS”, the role of integrators is key to delivering the right tools to the content authors, such as templates and content types set. Their ability to execute their daily tasks with autonomy and agility depends on what integrators will deliver and provide them with the best experience using the...
-

What is a Digital Experience Platform (DXP)?
Short definition A digital experience platform (DXP) can be used to build websites, portals, applications, and other digital products that optimize their visitors' user experience by using personalization, aggregation of various services, and different integrations. As a result, these experiences will be excellent at driving conversion and customer satisfaction, unlike what a traditional CMS could...
-

Jahia is going Cloud first!
Reflecting on our Cloud journey It has been five years since Jahia Cloud was launched, and it’s been an incredible journey. We have hit major achievements such as moving most of our business to the Cloud, hosting extremely demanding websites, and achieving unparalleled ease of use that allowed all Cloud customers to upgrade to the latest and greatest version of our software without downtime or hurdles....
-

Customizing pickers in Content Editor 4.1
When contributing web pages, editors have to create links to other pages of interest for the visitors, use or reference contents which have been created in different locations on the site, add images coming from the DAM, etc. For all of these tasks, they need to go through a “picker” interface, so they can select the desired resources. Jahia provides a set of such pickers out-of-the-box, which are generic enough to address the most common use cases. But did you know that you can customize them to ease the content reference selection for your contributors?
-

How Integrators Can Design the Ultimate Content Author Experience in a CMS? (Integrators Tips Pt.1)
Business team efficiency has become key in a fast-growing digital economy for all industries. As an integrator, you can help provide the necessary agility and autonomy needed for organizations to stay afloat and face competition effectively using the right digital tools. This is especially relevant to their content and website presentation. This makes the case for CMS platforms as a fundamental...
-

What do our clients say about us ? - APEC
Meeting with Hélène Catinaud, Head of Research and Development at APEC's Information Systems Division. Apec is the french employment agency for executives. The origin of the project Before 2015, APEC, a key player in the executive skills market, was using two CMS developed in PHP, while the rest of their developments were done in Java. The organization wanted to harmonize the technologies used by switching...
-

What You Need to Know About Security When Choosing a Cloud Content Management System
The repercussions for enterprises of cybersecurity breaches are significant and go far beyond lost data, including penalties for reparations, payouts for reparations, broken customer confidentiality, and, ultimately, lost customers. Never before in history has there been so much data and so many challenges in protecting it. Every touchpoint in your Digital Experience Platform (DXP), whether hosted...
-

Internal search engine: 4 best practices to improve your visitors' web experience
If user experience is an important factor in your digital strategy, then having a performant search engine on your website or your web portal is essential. The people who use the search engine on your website are : In the position where they already know exactly what they are looking for, or in the position where they have not found sufficient information during the navigation and want to learn more. ...
-

How to migrate to Jahia Cloud in 5 steps ?
The process of converting a system from on premise to Cloud is often described using a series of straightforward actions that eventually result in a migrated platform. Additionally, while most agree that migrations can be done in a matter of hours or days, one has to consider that information gathering and team-scheduling will account for a majority of the effort. This blog is intended to help existing...
-

4 steps to personalize your customers' web journey
Jeff Bezos said "If you build a great experience, customers tell each other about that. Word of mouth is very powerful." This means that a bad experience can hurt your brand image and drive customers to your competitors. Personalizing your customers' experience by offering them content adapted to their needs is essential to capturing their attention and increasing conversion and engagement. What is...
-

Headless CMS - Which features for Marketers?
Many companies want to embark on a headless project without considering the real impact that this technology can have on their business. Headless CMS make a lot of promises and highlight their "omnichannelity" and compatibility with different media such as mobile applications, connected watches, voice assistants, IOT... However, this vision is very optimistic and during real projects of voice assistants...
-

5 steps to set up a site factory
Is your business evolving? Do you have new content management needs? Are you wondering how to deliver experiences that are consistent with your brand’s image as your communication channels multiply? The Site Factory may be the answer to your questions! What is a site factory? It is important to start by explaining the difference between a multi-site structure and a site factory, two concepts that...
-

Resurrecting the Portal
What Covid taught us about self service, worker shortages, and the value of Portals. We know Portals aren’t currently the sexiest software out there, but the past 18 months have shown us their value is higher than ever. Once upon a time, Portal software and Portal websites were all the rage, but these days they are regarded as a legacy burden that is kept on life support until it can be sunset. The...
-

5 ways to boost your SEO performance
SEO is one of the best ways to drive traffic to your website. You should therefore bear this in mind when considering your digital and content strategies. Search Engine Optimization includes any techniques aimed at improving your website’s ranking in search engine results pages. If you’re not an SEO expert, don’t fret! To help you understand it more clearly, here are 5 ways you can improve your SEO....
-

How to approach a migration from Jahia 7 to Jahia 8
Jahia 7 was first released in 2014. Six years later, we decided to rebuild our UI and do major back end upgrades which led to the release of Jahia 8. Traditional Jahia upgrades usually consist of simply running an upgrade patch; however with the major changes introduced in Jahia 8, your implementation will need to be reviewed and updated. Depending on the plugins, configurations, and integrations you...
-

Digital Accessibility – The First Step Towards Personalization
So, you want to improve your model for winning and keeping customers? Did you float the idea of personalizing the customer experience? You’re on the right track! But did you know that the first step towards personalization should involve your website’s accessibility? Were you thinking more along the lines of A/B testing? Segmentation? Customer data? If so, don’t panic! One doesn’t preclude the other....
-

Jahia’s new extendable user interface (UI) in action
The UI of Jahia 8 is using the latest technologies and can easily be extended by developers, but what does it mean for content contributors? It means more flexibility for any custom requirement or integration need that you may have! In this article, we'll review 6 examples of Jahia 8 UI extensions: Adding a new panel in jContent, to manage releases of content Adding a new panel in jExperience to...
-

What do our clients say about us ? – Lyon Métropole Habitat
Focus on the collaboration between Lyon Métropole Habitat and Jahia with Christophe Simon, Project Manager in the IT Systems Department. Lyon Metropole Habitat, the leading social housing entity in the Lyon metropolitan area has been managing their website and client extranet on the Jahia platform since their creation in 2016. Their website, www.lmhabitat.fr, is one of the main focal points for browsing...
-

The truth about Headless
Before writing this blog post, I spent a lot of time reading what the Internet had to say about Headless. Blog posts were often partisan or biased by their authors’ points of view—a common occurrence when it comes to Headless—and focused mainly on the technical benefits of the approach. We’ve spent recent years working together on a large number of Headless, Hybrid and Traditional CMS or DXP (Digital...
-

Jahia’s Open Source DXP Portal Development
How web portals in java help you integrate digital experiences across different touchpoints to give your customers both personalization and consistency
-

Java Based CMS Built on Apache Tomcat
Running Apache Tomcat is an effective way to run a java based, open-source content management system (CMS), and create dynamic content for your readers.
-

How to Elevate Your CX with Personas, Customer Journey Maps, and Content Auditing
There’s no doubt that CX matters, but it takes truly understanding your customers to make it happen. A structured approach can make all the difference. Let’s take a look at how to use personas, customer journey maps, and content audits to level up your CX.
-

Headless CMS: Paas vs Self-Hosted
Running a Headless CMS in a PaaS environment is the perfect scalable, cloud-based solution for hosting your content. Jahia’s jContent and Headless CMS solutions combine the best of both.
-

Open Source CMS: What is it and do I need it?
In this post, we’ll examine what an open source CMS is, how it works, and who can benefit from the software the most.
-

5 Website Personalization Best Practices (+Free Tool)
Whether you are just starting your website personalization journey or looking for a tune-up, these 5 best practices for website personalization will help improve your marketing efforts.
-

Headless CMS: Jahia Reviews The Best Headless CMS of 2021
In this post, we’ll examine some of the best headless CMS solutions on the market and how they can help your business grow.
-

Data From The Ground Up
Too often, the conversation about customer data is focused on how it can service content, rather than how it can better serve the long-term goals of your organization. When used effectively, customer data empowers efficient user journeys and strong customer relationships.
-

What is a Headless CMS?
In this post, we’ll detail what a headless CMS is, how it works, and how it can benefit your organization.
-

Choosing The Best Customer Data Platform: Top Vendors Compared
In this post, we’ll examine the benefits of using a CDP and share our list of the 10 best customer data platforms available today.
-

Strengthening Your Consumer-Brand Relationship Starts with First-Party Data
With Apple & Google closing up shop when it comes to third-party cookies, the martech space is in flux - but building strong consumer-brand relationships starts with first-party data.
-

CDP vs DMP: Key Differences You Need to Know
In this CDP vs DMP comparison, we’ll analyze the key differences between the two platforms to see which is more useful to your business.
-

The Top Customer Data Platform Use Cases
In this post, we’ll examine the most popular customer data platform use cases and how they can benefit your business.
-

Open Source Digital Experience Platforms: The Key to Great Customer Experiences
In this post, we’ll examine how your organization can benefit from an open source digital experience platform and what to consider when choosing a solution.
-

5 Ways DAMs Can Improve Digital Experience Creation
In this article, we take a look at 5 of the top reasons why integrating a DAM/PIM with a DXP leads to more engaging Customer Experiences.
-

Personalization Strategy: Achieving Personalization at Scale
63% of digital marketers report that they struggle with personalization (Gartner). In this post, I’ll walk you through how to achieve meaningful personalization at scale.
-

Breaking Down The Three Types of CDP Data
CDP data assemble! A CDP is built very much like a news team. It consists of multiple different data types and delivery vehicles. When combined, they become a powerful team.
-

Maximize Operational Data with Jahia's Embedded CDP
If data is the new gold, then consider the rush well and truly underway.
-

The New Corporate Power Couple:
CMOs + CIOsWhen the CIO and CMO are in alignment, they become the c-suite power couple the business world has been waiting for.
-

A Streamlined Martech Stack is Critical to Digital Success
To deliver a modern customer experience, only a joint Marketing & IT strategy will suffice.
-

How Do You Know It’s Time For Digital Transformation?
You’re staring down the barrel of a dwindling Sales pipeline, with prospects that are unengaged with your content. Digital transformation may be the solution.
-

The Importance of Flexibility Across your Application Ecosystem
The digital renaissance is in full swing across the business realm; no matter if you’re in government, healthcare, finance or any other specialized industry — the expectation is that you’ll be providing an engaging digital service, one that can cater to a broad spectrum of user processes and workflows.
-

The Journey of a Design System
Jahia Solutions is an amazing company that I have had the privilege of being a part of for the last year. We have embarked on the journey many other companies have, the pursuit of a design system. This is my take on our journey so far.
-

3 ways 2021 will be digitally different
2020 was a huge struggle for individuals and businesses, but it did also bring progress, as it transformed work-life balance into work-life blended.
-

Why You Should Assess Your Digital Experience Stack (DXS)
A company's digital presence is as an integral part of the customer journey and overall business success. From your website to your social media to the very product you sell, every digital channel in which you “touch” your customers is part of their overall Digital Experience (DX). To make planning your digital experience stack simpler, we’ve created a 10 step DXS checklist to help you make the right stack choices.
-

Jahia + Widen = Marketing Stacks are Built, not Bought
Jahia's new technology partnership with Widen furthers our goal of empower companies to build marketing technology stacks specific to their needs.
-

What is a True DXP?
The term “DXP,” or Digital Experience Platform, is tossed out by a lot of companies nowadays. But what exactly defines a DXP can be unclear.
-
DXPs and the B2B Lead Funnel
If you're a B2B marketer, you have a lot of things to worry about. At the top of that list, is generating leads and pipeline for your organization.
-

The "DXP Creep"
It’s the Halloween season, and you know what that means: ghost stories!
-

The “Hip Hip Hooray” of HIPAA Compliance
Did you hear? Jahia is now HIPAA compliant thanks to the ongoing work of our compliance and data security teams! You can practically hear the cheers echoing out of our socially distant office spaces. HIPAA is probably the best known US healthcare regulation since it was originally passed in 1996. Originally focused around the idea of health insurance portability, wherein you could take your employer-paid...
-

Is It Time To Re-Evaluate Your Digital Strategy?
Digital strategies ultimately guide how your organization builds out its technology, adapts to changes in the market, and builds a sustainable engine that delivers real ROI for your digital marketing and organizational efforts.
-

Hey Look, We Got An Award!
The MarTech Breakthrough Awards just announced that Jahia’s jContent solution has won their Best Content Management Platform award for 2020.
-

The (High) Costs of DXP Suites
Whether you’re in the process of buying a DXP or just on the hunt for more information, we’re here to explain the cost difference between the suite and stack approach.
-

CMS vs. DXP — What’s The Difference?
It’s that age-old dilemma: Cheese vs. quiche. Apples vs. pie. CMS vs. DXP.
-

What Is a Content Management System?
Have you ever heard the phrase “Content is King?” Well, if you’re a marketer or IT professional, this isn’t just an overused idiom – you are literally servant, maid and serf to the content that your organization produces on a daily basis.
-

It's Time to Stack Up, Not Suite Out
t’s a question that’s dogged the technology world for decades. The crux of this debate revolves on whether it’s better to enshrine your marketing technology in the walled-garden of a single Tech Giant or entrust it to the wild west of smaller, more agile Challenger Tech companies.
-

Innovation Through Iteration
Jahia’s latest update is built to adhere to the iterative mindset. Instead of going for the big fireworks display that often accompanies a flashy acquisition or new piece of software, we took a step back and answered three key questions.
-

Simplifying the Digital Transformation
The world has gone digital. You know it and your customers know it. We at Jahia know it and our customers know it. Unfortunately, knowing is only half the battle!
-

Creating A Progressive Web App In 2 Weeks - Part 2
Alex and Lars have developed content definitions and are ready to start linking the app. Will they make the 2 week timeline? Find out in the 2nd part of their story!
-

Creating A Progressive Web App In 2 Weeks - Part 1
At Jahia, we are committed to making digital simpler. To that end, we decided to run an experiment: Could an agency with no prior experience with Jahia create a new web app within 2 weeks, utilizing Jahia's Content & Media Manager as a headless CMS? This is 1st part of that story
-

What Is a CDP?
CDPs, or Customer Data Platforms, have recently become a hot-button topic of conversation. Mentioned usually, but not always, in the same breath as DXPs. Now, while we wouldn’t necessarily say that it’s incorrect to pair these two together, it is important to know that DXPs and CDPs are not the same thing.
-

What is Headless?
“Headless” has become one of the most buzzed-about terms in the industry as of late. Headless-enabled. Headless-first. Headless-optional. We even mention such enablement in our own products. But if you’re not familiar with what this means – or the incredible effect it can have on your CMS – it can just come off as gobbledygook. So, as always, let’s make it simple!
-

Top Four Ways To Prepare For The "Headless" Revolution
February is Jahia’s month of Headless! Each week, we will be sharing a new blog post dedicated to helping you navigate the rocky seas of Headless technology and capabilities. This week, we'll be diving into the top four ways you and your company can ready yourselves to hit the ground running!
-

What Do We Mean By “Making Digital Simpler?”
It’s our slogan. Our motto. Our raison d'être. “Making Digital Simpler” defines the very essence of what Jahia is and what we do, and as such has been a regularly-featured phrase on our products, our websites, our tchotchkes, and even the banners we take with us to tradeshows. But what does it mean?
-

Customer Highlight - BNP Paribas
As a leading multi-asset provider in all these competitive international markets, BNP Paribas Securities Services needs to effectively stand out. This all starts with their website, the entry point for many of their prospects.
-

What is a Digital Experience Platform (DXP)?
One of the most common questions we receive is “What is a DXP?” It’s not hard to see why – since the term was introduced a few years ago, seemingly everyone has come up with their own definition for it. From Gartner to Forrester to the tech blog your friend reads during their lunch break, these three letters have been dissected more than a high school pig cadaver.
-

Welcome to Jahia Blog v1.5
A new year means new changes. Unlike our commitment to hot yoga, though, these changes are exciting in a way that won’t leave you gasping for breath afterwards. Let us tell you a bit about them: